

 The big tree growth from a book isolated on white background[/caption]
The big tree growth from a book isolated on white background[/caption]
Today, crop breeding involves meticulous observations of plant phenotype data, in search of the underlying genomics that would confer the traits that would make for better food to feed a growing human population. Research generates huge raw datasets that are used by researchers to discover the plants of the future.
When looking at global crop production based on data from the United Nations’s Food and Agriculture Organization (FAO), one can see that between 1965-1985 crop yields grew by 56%, compared to only 28% from 1985-2005. The enormous successes in 1965-1985 are a result of the “Green Revolution” which harnessed pesticides, fertilization and innovations in irrigation, soil conservation and mechanization. Today, the world needs a new revolution if it is to feed the billions of humans on the planet.
We believe this new revolution will be based on data science and predictive algorithms. It will based on sharing public research data and harnessing its power. We believe this new revolution will happen when the enormous power of the hundreds of genetic studies (relating to plant species, population types, environmental conditions and locations) will be harnessed into a big data store where all their power can be unleashed.
Yet the truth of the matter is that today, all this public data, generated by research, goes nowhere. Some of it is irretrievably lost. It is not stored in a way that makes it accessible and that preserves its enormous value. Annual public plant research costs millions of dollars and yet datasets are published statically and partially in scientific journals and the underlying data is left to waste in the researcher’s spreadsheet files.
Rice, a staple of a huge part of humanity, is a prime example. Hundreds of studies have been conducted in rice (Oryza sativa). They involved genetic marker analysis of segregated populations of the two rice subspecies indica and japonica. Yet, amazingly enough, the raw phenotypic data for these studies are lost.
This is what our Project Unity, now in closed beta, is set to correct.
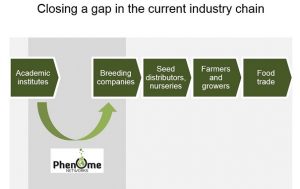 Project Unity is a platform that will host all phenotype-to-genotype public-domain data in a common and unified platform, offered as a free service for academia. Each researcher will be able to load their data and connect it to existing global knowledge, by linking traits to ontology, markers to genetic/physical maps and germplasms to pedigree and their sources. Initially, each dataset is stored privately, and can only be accessed by the researcher comparing his results to public ones. Data is made public once the researcher decides to do so typically after the publication of the corresponding scientific paper.
Project Unity is a platform that will host all phenotype-to-genotype public-domain data in a common and unified platform, offered as a free service for academia. Each researcher will be able to load their data and connect it to existing global knowledge, by linking traits to ontology, markers to genetic/physical maps and germplasms to pedigree and their sources. Initially, each dataset is stored privately, and can only be accessed by the researcher comparing his results to public ones. Data is made public once the researcher decides to do so typically after the publication of the corresponding scientific paper.
